
Overview
inf6.com is a paper knowledge workspace with arXiv / PubMed support. You bring papers in, ask questions per paper (and per page), store the explanations, and keep them attached to that paper.
By accumulating “question → explanation” per paper, you maintain a reusable knowledge base that grows with your reading—without losing context or mixing sources.
Storage: outputs are saved as files in a folder you choose in iCloud Drive, shared across iPhone / iPad / Mac.
概要
inf6.com は、arXiv / PubMed 対応の「論文ナレッジ整備」ワークスペースです。論文を取り込み、論文テキストに対して問いを立て、得られたAI解説を「その論文に結び付けて」蓄積します。
論文単位で「問い → AI解説」を積み上げることで、文脈を失わず、混線せず、再利用できる知識体系を育てていくことが可能です。
保存方式: 生成物は iCloud Drive の任意フォルダにファイルとして保存され、iPhone / iPad / Mac 間で共有してご利用いただけます。
Main Features
arXiv / PubMed integration Main
Search, fetch, and organize papers from arXiv and PubMed, then keep all knowledge attached to the paper you are working on.
Per-paper “question → explanation” accumulation Core
Store your questions and AI explanations per paper, so knowledge stays attached to the source and remains reusable.
Assets pipeline (Figures / Tables ) Extract
Scan pages and extract figures, tables as review-ready assets attached to the paper.
Notes marking per paper Notes
Keep your own notes alongside accumulated explanations, so each paper becomes a coherent learning unit.
Formula clips (mini PDF) Clip
Clip important formulas into mini PDFs for quick revisiting, and attach explanations linked to the original paper.
iCloud Drive folder sharing Share
Save outputs as files in a folder you choose in iCloud Drive, shared across iPhone, iPad, and Mac.
Roadmap Planned
Planned: Core ML / Neural Engine–accelerated semantic reranking + RAG-style paper search.
Goal: keep the current “file-based iCloud Drive” workflow, while adding on-device semantic scoring for arXiv/PubMed candidates.
Phase 1: No-model baseline First step
- Fetch abstract + minimal metadata (categories/MeSH, dates, ids).
- Rule-based filtering to avoid oversized results.
- Stable file-based saving to iCloud Drive (PDF + sidecars).
Phase 2: On-device reranking Core ML
- Generate embeddings on-device and compute similarity against a profile vector.
- Rerank candidates without sending paper content to servers.
- Keep the current workflow: same iCloud Drive folder across devices.
Phase 3: RAG-style search loop RAG
- Use the profile to iteratively refine categories/subcategories.
- Maintain a local cache of metadata/vectors (optional).
- Expose “why recommended” signals (categories, abstract similarity, etc.).
主な機能
arXiv / PubMed 連携 主機能
arXiv および PubMed から論文を検索・取得し、作業対象の論文に紐づけてナレッジを整備できるようにします。
論文単位の「問い → AI解説」蓄積 中核
論文ごとに「問い」と「AI解説」を保存し、出典に紐づいた形で再利用できる知識へ整えます。
図表パイプライン(図・表) 抽出
論文ページを走査し、図・表を抽出して、復習用の素材として論文に紐づけて保存します。
論文単位のメモ・マーキング メモ
ご自身のメモをAI解説の蓄積と並べて保持し、論文を「学習単位」として一貫した形に整えます。
数式クリップ 切り出し
重要な数式をミニPDFとして切り出し、元の論文に紐づけてAI解説を付与することができます。
iCloud Drive フォルダ共有 共有
生成物は iCloud Drive の任意フォルダへファイルとして保存され、iPhone / iPad / Mac 間で共有してお使いいただけます。
Samples
inf6 includes sample study materials for E-shikaku and G-kentei as examples of how a paper knowledge workspace can be organized.
These are provided as samples. inf6 itself is a general-purpose workspace for building per-paper knowledge.
サンプル
E資格/G検定 の学習サンプルを収録しています。「論文ナレッジ整備」をどのように構成できるかの具体例です。
※ サンプルは例示です。inf6 自体は、論文単位でナレッジを育てる汎用ワークスペースです。
Figures / Formulas / Tables
図 / 数式 / 表


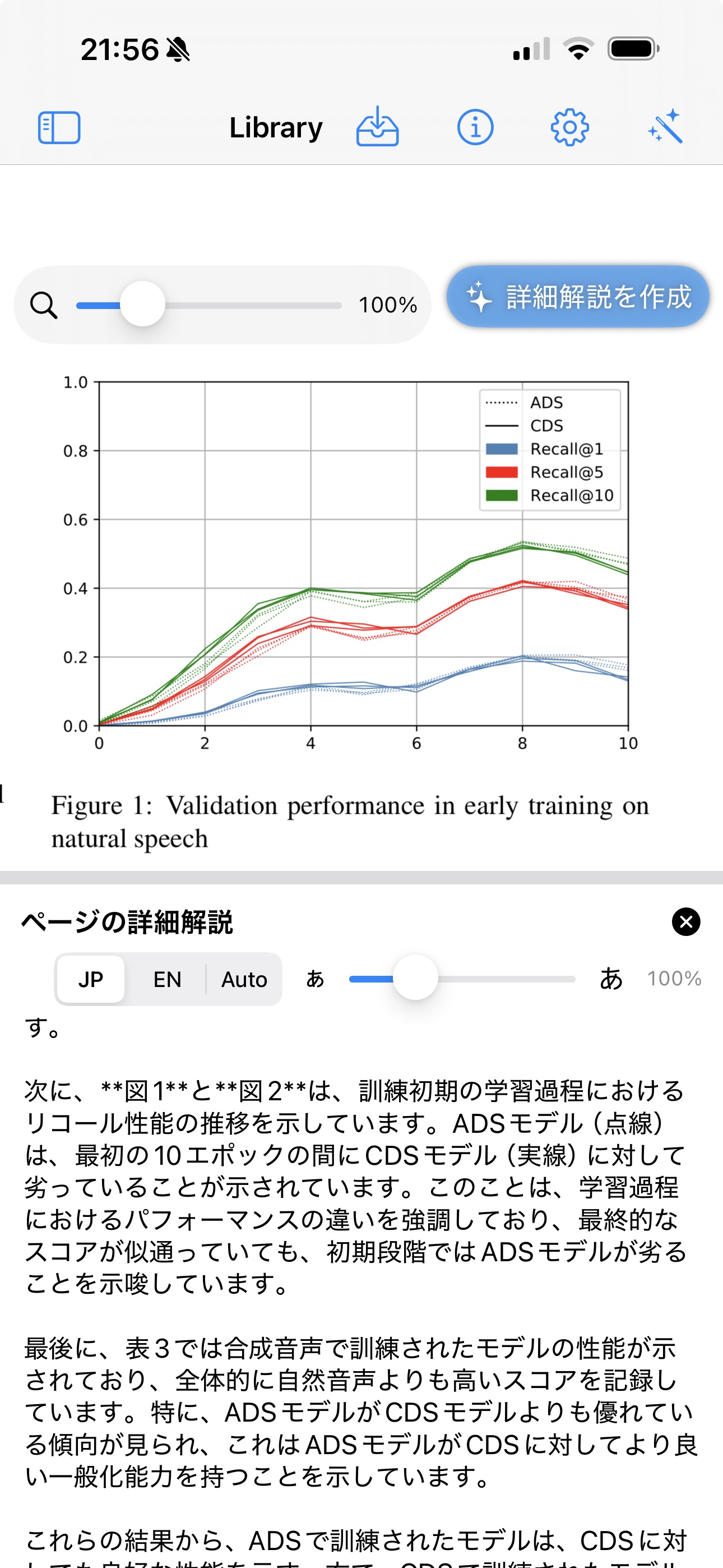
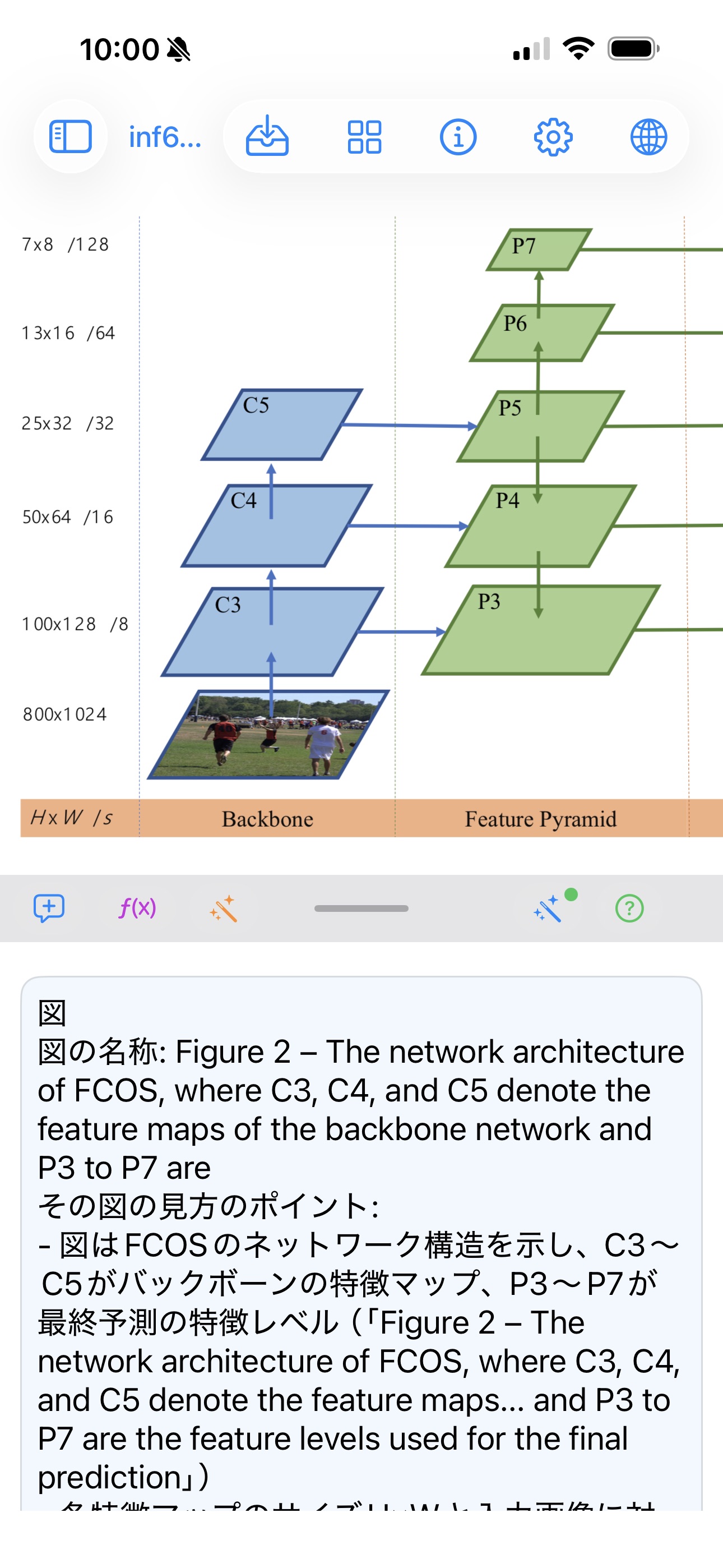
iPhone / iPad
iPhone / iPad

開発計画 予定
予定:Core ML / Neural Engine を活用した、端末内の意味スコアリング(リランキング)+ RAG型の論文探索。
既存の「iCloud Drive にファイル保存して端末間共有」という設計は維持しつつ、arXiv / PubMed の候補を端末内で“必須っぽい順”に並べ替える導線を追加します。
Phase 1:モデルなしの基礎 第一段階
- 要旨+最小メタデータ(カテゴリ/MeSH・日付・ID)を取得。
- ルールベースで過大な結果を抑制。
- iCloud Drive へファイル保存(PDF+サイドカー)を安定化。
Phase 2:端末内リランキング Core ML
- 端末内で埋め込み生成→プロファイルとの類似度で並べ替え。
- 論文本文をサーバへ送らずに“必須候補”を先頭へ。
- 端末間共有は「同じiCloud Driveフォルダ」を前提に維持。
Phase 3:RAG型の探索ループ RAG
- プロファイル→カテゴリを段階的に絞り込む。
- メタデータ/ベクトルのローカルキャッシュ(任意)。
- 推薦理由(カテゴリ、要旨類似など)を可視化。
How it works
1) Bring a paper in (arXiv / PubMed / local PDF).
2) Ask questions and store explanations. Keep “question → explanation” attached to the paper (and page when needed).
3) Accumulate and reuse. Over time, each paper becomes a stable knowledge unit you can revisit.
使い方
1) 論文を取り込む(arXiv / PubMed / 手元のPDF)。
2) 問いを立て、AI解説を保存する。 論文(必要に応じてページ)に紐づけて「問い → AI解説」を蓄積します。
3) 積み上げて再利用する。 継続することで、論文単位の安定したナレッジが育ちます。
Setup
Required: AI features need an OpenAI API key. The key is stored in Keychain and can be synced via iCloud Keychain.
- Create an API key at platform.openai.com/api-keys.
- In the app, open Settings → “OpenAI API Key”, then paste the key.
- Open any paper and run an explanation. If the key is missing/invalid, the app will show an error.
Some paper services may request a contact email for responsible usage. Configure it in the app only if needed.
設定
必須: AI機能には OpenAI APIキーが必要です。キーは キーチェーン に保存され、iCloudキーチェーン により同期可能です。
- platform.openai.com/api-keys にてAPIキーを作成します。
- アプリの設定で「OpenAI API Key」を開き、キーを貼り付けます。
- 任意の論文でAI解説を実行し、未設定/不正な場合はアプリがエラー表示します。
論文サービスによっては、責任ある利用のために連絡用メールアドレスを求められる場合がございます。必要な場合に限り、アプリ内で設定してくださいませ。
Storage
Outputs: saved as files in a folder you choose in iCloud Drive.
Sharing: the same folder can be used across iPhone / iPad / Mac.
Key storage: your API key is stored in Keychain and can sync via iCloud Keychain.
保存と共有
生成物: iCloud Drive の任意フォルダへファイルとして保存されます。
共有: 同一フォルダを iPhone / iPad / Mac で共有してご利用いただけます。
キー保存: APIキーは キーチェーン に保存され、iCloudキーチェーン で同期可能です。
Contact
Support / bug reports: inf6.com@icloud.com
Legal / Privacy / Terms are available on legal.html.